Options and Settings possible in the SOFTplus GSiteCrawler
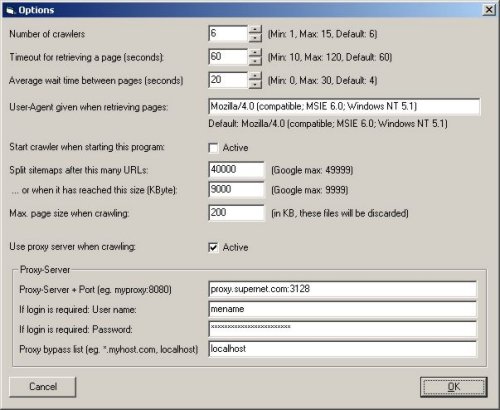
Number of crawlers
This is where you can specify how many concurrent crawlers the program should use to crawl websites. The default value of "6" seems quite good, I guess with a more powerful system (PC + downstream + server) you could use higher numbers. You can try and see. There is a limit of 15 crawlers and a minimum of 1 (which I wouldn't recommend :-)).
The more crawlers you have working at the same time, the slower the program / computer will react to your input. You might want to keep this in mind and slowly work yourself up and see where the limit of your system is instead of just setting it to 15.
Timeout for retrieving a page
This is the general timeout in seconds used when retrieving a page from the internet. The timeout is used as follows:
- DNS Resolve timeout - time needed to resolve the name via DNS: default values based on your operating system (client DNS service).
- Connect timeout - time needed to establish a connection to the server: full duration specified here
- Send timeout - time needed to send the request: full duration specified here
- Receive timeout - time needed to receive ONE packet of information. Pages are generally split into several packets, this timeout is valid for each page. If one page times out, the whole request will time out. This also uses the full duration specified here.
So for example, assuming we leave 60 seconds (default), the program can take up to 60 seconds trying to resolve the DNS name (this depends on your operating system), then up to 60 seconds to send the request and then up to 60 seconds to receive each packet. Assuming there are 10 packets being sent (the size of a packet can vary), it would allow for maximum 60 seconds DNS resolution, 60 seconds for the initial connection, 60 seconds for the request and then up to 60 seconds to receive each packet; altogether a total of 13 minutes for 10 packets ... but in reality, if the server or the connection is this slow, it'll time out somewhere along the way.
After a time-out the URL will be placed in the bottom of the crawler queue and will be retried in random intervals, up to 10 times, before it is completely aborted and put on the aborted list.
Average wait time between pages
This is the average time which is used between requests of a crawler. A crawler will wait for a minimum of 1 second and then, using a random variation, an average of the time you specified here. So if you specify 10 seconds, it might try the next URL after 1 second, after 10 seconds or after 20 seconds - the average wait time will be 10 seconds though.
The reason for this setting is to give slower or bogged down servers some time to breath between requests. Remember that this wait time will be used on each crawler separately, i.e. if you have a large number of crawlers, you will still be sending a lot of requests to the server.
User-Agent given when retrieving pages
This is the "user agent" passed on to the server when retrieving pages from it. By default, it specifies the Microsoft Internet Explorer 6.0 running on a Windows 2000 system. If you wish to keep your crawls "hidden" on the server logs, this is a good choice. If you are logging user-agents on your server, by specifying a different user agent (e.g. "GSiteCrawler"), you will be able to determine how many accesses are from real users and how many came from the GSiteCrawler.
Note: if you specify a non-browser user-agent (e.g. "GSiteCrawler") you will not be able to import URLs from Google. This is something Google has implemented to keep automated programs from accessing their search system through the web-interface. Since the GSiteCrawler only accesses Google once (if at all) per project, I wouldn't count it as an "automated program". If Google should decide differently in the future, this function might have to be removed or changed.
Start crawler when starting this program
You can close the program at any time, even if there are further URLs in the crawler queue. By placing a checkmark here, the program will automatically start the crawler when it is restarted. This is not always a good idea (if your queue is large, if it bogs down your system or if you want to test other options), so it is possible to turn this off.
Split sitemaps after this many URLs / or when it has reached this size
According to Google, a Google Sitemap file may have up to but not including 50'000 URLs and have a maximum size of 10MB. After this limit, you must split your URLs into several sitemap files. The program will do this for you automatically, and if you wish, you can split your file even earlier. Also, it will automatically create sitemap-index files (which you can submit to Google instead of all the sitemap files).
Max. page size when crawling
Any pages which are larger than this limit will be discarded and placed into the aborted URL list. The reason behind this is that some sites send files (downloads) through "normal" URLs - these files are generally not HTML pages and cannot be parsed. Similarly, a badly configured server might send never-ending pages (usually filled with error messages; ah, so much fun). Larger pages are discarded completely, i.e. not crawled at all.
Use proxy server when crawling
Actually, this setting is used for all http / https access. You can specify a proxy server, with port, a username, password (if required) and a proxy bypass list (servers which should not go through the proxy server).
Specifying these options via editor
These settings are saved in the GSiteCrawler.ini file, which can be edited with any normal text editor (e.g. Notepad). These settings may be changed within the INI-file directly, if so desired. It's not exactly the idea behind the settings, but if for any reason the option window should not be accessable (e.g. your crawler starts automatically and your settings bog down the computer completely), you can change them directly. You will need to do this when the program is not running.